Documentation,
ripped offline.
Turn any docs site into a clean, searchable, offline Markdown archive. Ready to grep, version, embed, or hand to an LLM.
Save 31× on LLM tokens.
Strip boilerplate HTML. Cache with Anthropic Prompt Caching. Pay micro-cents instead of dollars.
Every query refetches full HTML with nav, sidebar, scripts.
Clean MD loaded once. Prompt caching slashes subsequent reads 90%.
A typical docs page is 70–90% boilerplate (nav, sidebar, footer, scripts). Docurip strips it all: ~80–150 KB raw HTML becomes ~10–25 KB clean Markdown.
Live-fetch tools crawl per question, paying the full HTML price each time. Docurip's merged MD loads once into context — no redundant requests.
Anthropic's cache reads cost ~10% of normal input tokens. Cache the merged MD once and subsequent queries drop to micro-cents.
Built with Rust + Tauri.
A documentation harvester optimized for speed, cleanliness, and developer experience.
Never lose context to the upstream.
Set a start URL, crawl depth, and page limit. Docurip walks the site in parallel, respecting robots.txt directives. For JS-rendered sites, it spins up headless Chrome on demand.
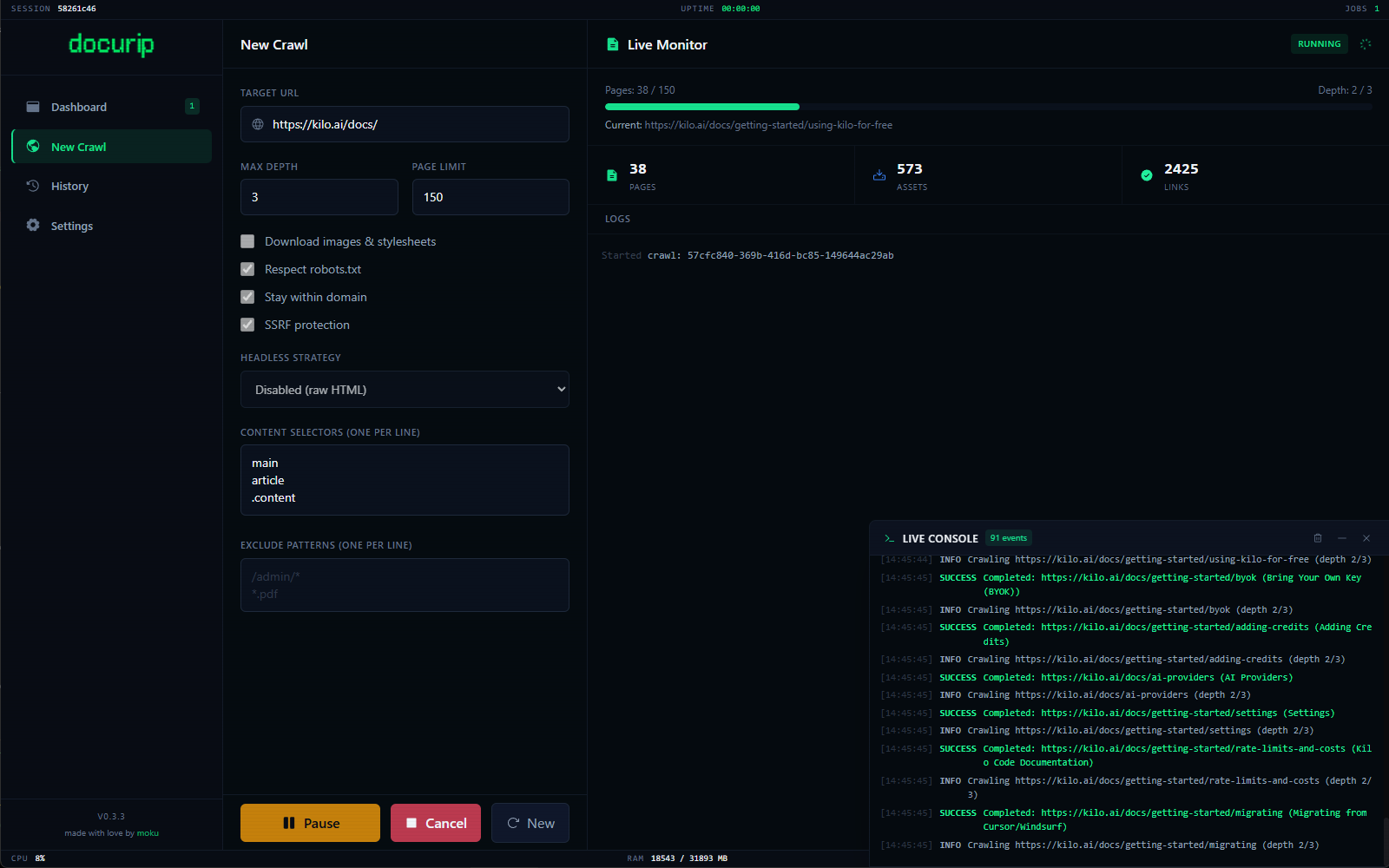
Real-time metrics & velocity tracking.
Watch crawls execute live. Speedometer animations count pages per minute. Success/failure rates. Total download size. A console drawer streams every fetch as it happens.
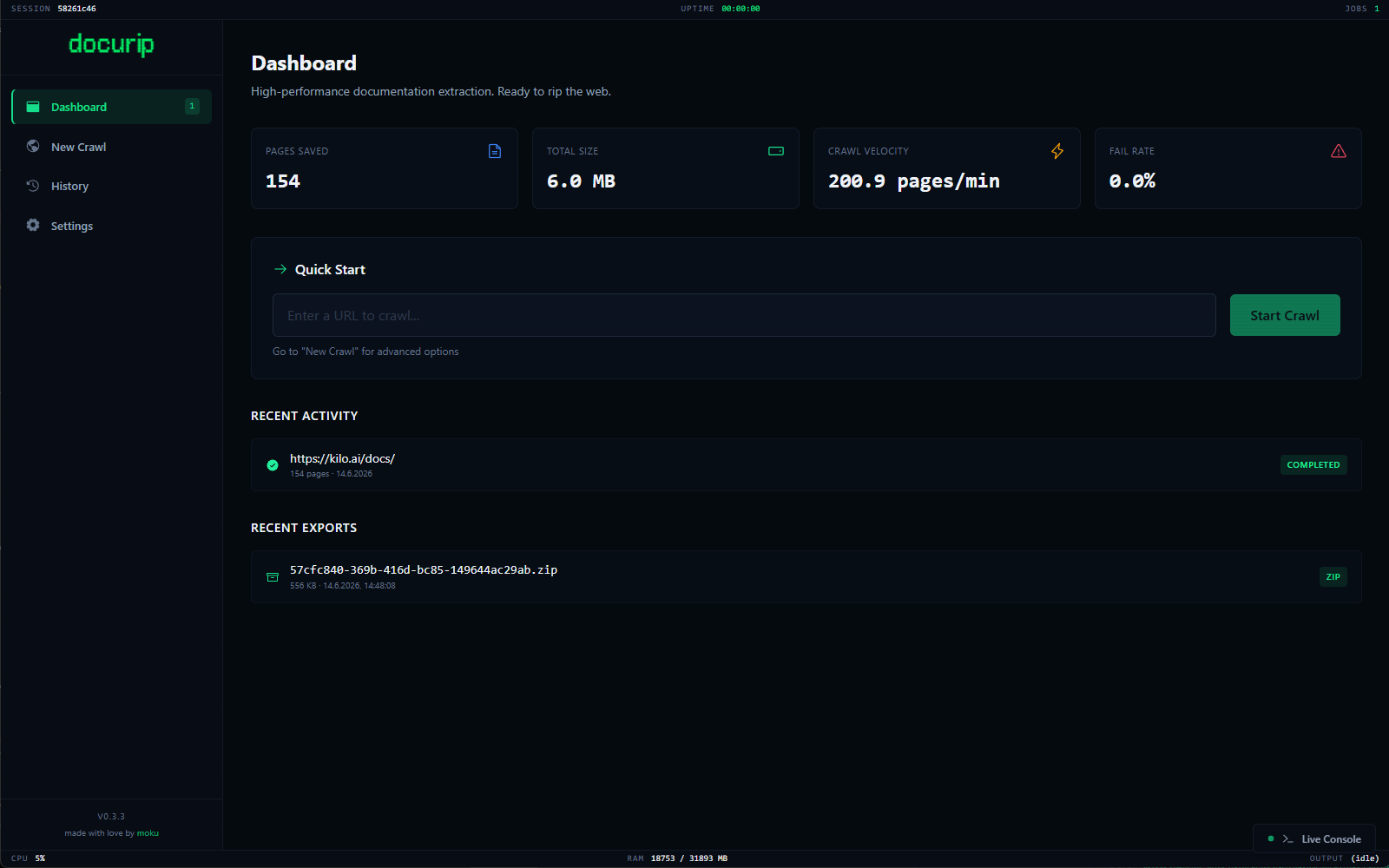
Built-in tree view & full-text search.
Explore your mirrored archive instantly. Debounced full-text search. Syntax-highlighted previews. Sandboxed rendering via DOMPurify to eliminate XSS risks.
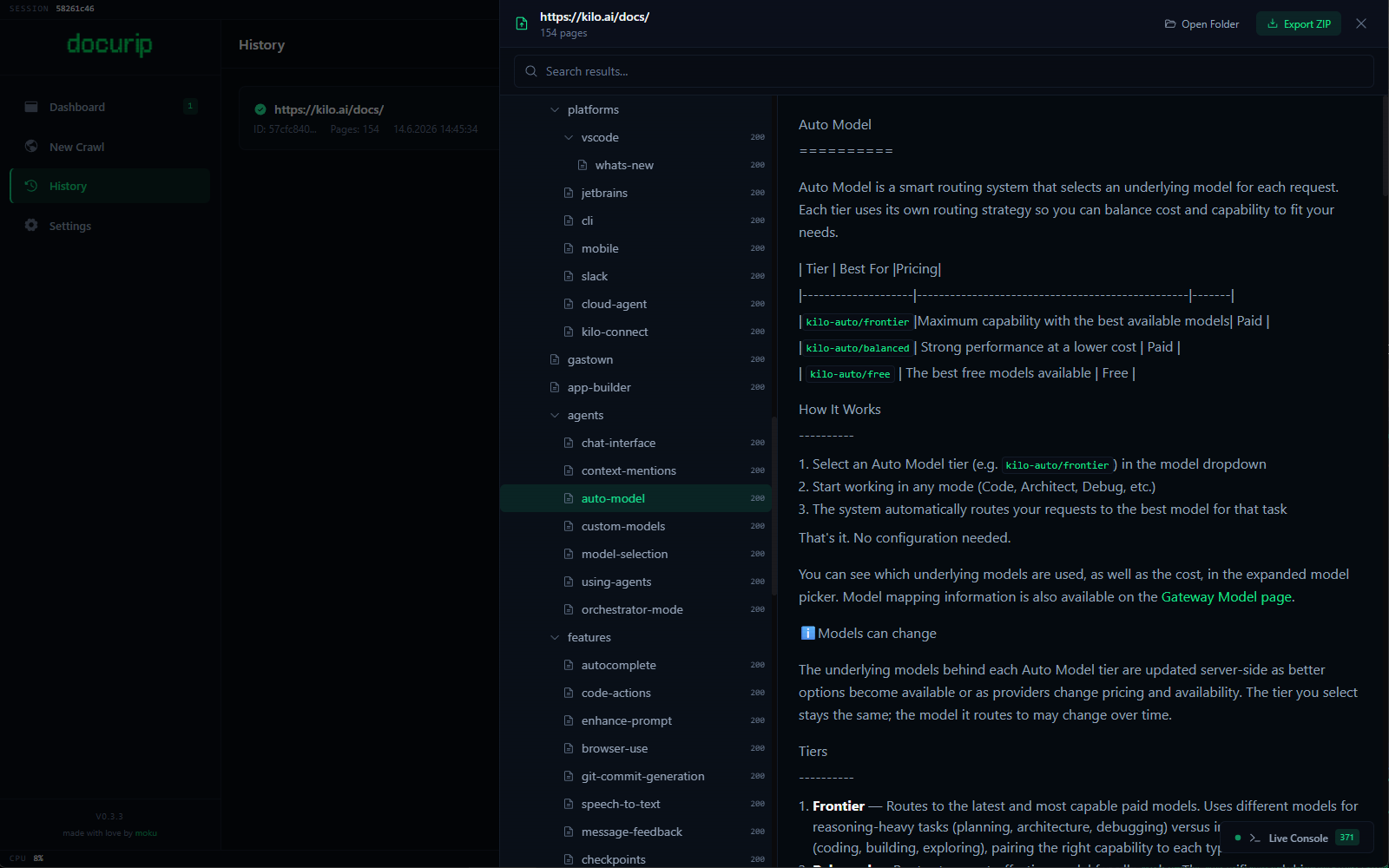
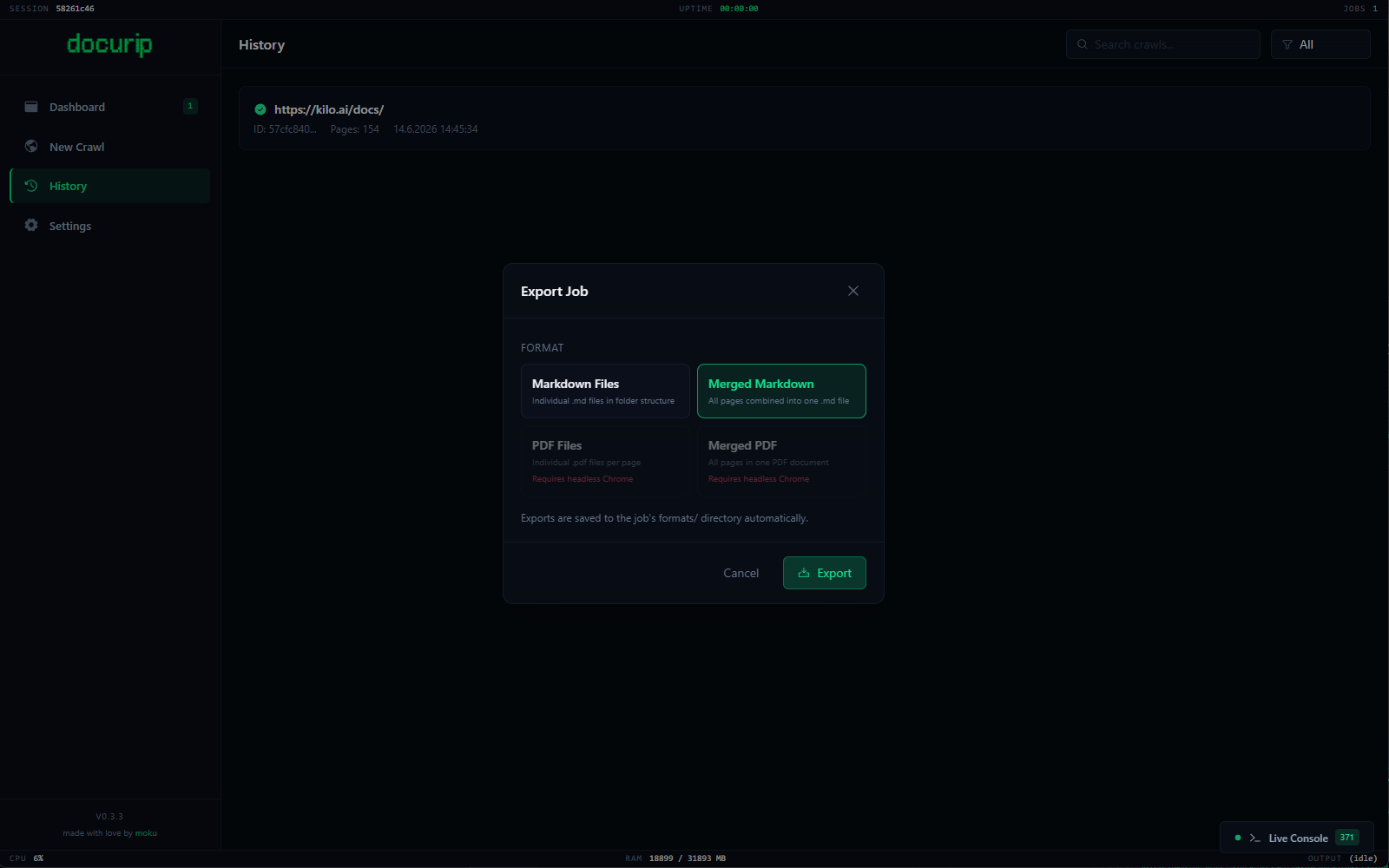
Stitch, compress, and ship anywhere.
Export as separate Markdown files, a merged handbook, PDFs, or a ZIP. Link rewriting ensures offline navigation works. Asset hashing deduplicates images and fonts.
Built to behave.
Engineered to protect your network, respect targets, and safeguard local disk space.
Locks crawling to your target host. Never drifts into external ad networks, vendor blogs, or partner sites.
Blocks localhost, RFC 1918 private ranges, and link-local addresses at launch. No accidental internal hits.
No unsafe-inline scripts. HTML sanitized through DOMPurify. Preview pane sandboxed with strict capabilities.
Pauses on disk full, permission denied, or read-only errors. Fix the issue, hit Resume, keep your progress.